binarized_network
Deep neural networks often suffer from over-parametrization and large amounts of redundancy in their models. Which call for many resources (processing power, memory, battery time, etc), and sometimes critically constrained in applications running on embedded devices.
Training such a deep neural networks was also computational demanding and time consuming. Thus recently many model compression methods were proposed, an extreme method is called the binarized network.
Straight Through Estimator
When quantization the network weights and activations with binary values, the biggest problem is the gradient back-propagation, cause the gradient of the binarization function is always zero. To overcome this, Straight Through Estimator was introduced by Hinton & Bengio.
Straight-Through Estimator:The idea is simply to back-propagate through the hard threshold function (1 if the argument is positive, 0 otherwise) as if it had been the identity function.
Binarization Functions
Many binarization functions were proposed till now, mainly based on the function:
-
Stochastically Binarization
- ,
where was scaled to or the probability was restricted to .
- ,
-
Deterministic Binarization
- ,
with or without a scaling factor .
- ,
Recent works
Bitwise Neural Networks
The author proposed a two-staged approach:
- A typical network training with a weight compression technique which help the real-valued model to be easily converted into BNN.
- The weights were compressed by , which wrap the weights to have value between -1 and +1.
- Similarly, is also chosen for the activation.
- Use the compressed weights to initialize the BNN parameters and do noisy back-propagation based on the tentative bitwise parameters.
- A sparsity parameter was introduced to decide the proportion of zeros after binarization, which decide a boundary , and the weights were divided into three group :
- , if
- , if
- , if
- The weights were updated with real-values parameters during the back-propagation progress.
- A sparsity parameter was introduced to decide the proportion of zeros after binarization, which decide a boundary , and the weights were divided into three group :
Thus, in the feed-forward only XNOR and bit-counting operations are used instead of multiplication, addition, and non-linear activation on floating or fixed-point variables.
BinaryConnect Github
In this work, only the weights are binarized, and the weights are only binarized during the forward and backward propagation but not during the parameter update.
- The real-valued weights are clipped within
- Batch Norm and Adam are used.
- The BinaryConnect are proved to act as regularizer.
- SGD explores the space of parameters by making small and noisy steps and that noise is averaged out by the stochastic gradient contributions accumulated in each weight. Therefore, it is important to keep sufficient resolution for these accumulators, which at first sight suggests that high precision is absolutely required.
- Noisy weights actually provide a form of regularization which can help to generalize better. And previous works showed that only the expected value of the weight needs to have high precision, and that noise can actually be beneficial.
Neural Networks with Few Multiplications
The author proposed a two-staged method:
- Stochastically binarize weights to convert multiplications involved in computing hidden states to sign changes.
- The weights are forced to be a real value in the interval .
- Quantize the representations at each layer to convert the remaining multiplications into binary shifts while back-propagating error derivatives (called quantized back propagation).
- The activations in back-propagation computation are quantized to be integer power of 2 to convert the multiplications into binary shifts.
A somewhat surprising fact is that instead of damaging prediction accuracy the approach tends improve it, which is probably due to several facts.
First is the regularization effect that the stochastic sampling process entails.
The second fact is low precision weight values. Low precision prevents the optimizer from finding solutions that require a lot of precision, which more likely correspond to overfitted solutions.
XNOR-Net Github
The author introduced a new way to binarize the weights and activations, and introduce a XOR-net which.
Estimate the real-value weight filter using a binary filter B \in \{+1, −1\}^{c×w×h} and a scaling factor \alpha ∈ R^+ such that . Then a convolutional operation can be approximated by \mathbf{I * W ≈ (I \bigoplus B)} \alpha.
- The new binarization method is to solve the optimization function:
J(\mathbf{B},\alpha) = \|\mathbf{W} − \alpha \mathbf{B}\|2
With the optimal solution of and :- Calculate gradient of as Binarized neural network: which has
- To further binarize the activation, similar to the previous method, the dot product between is approximated by , where \mathbf{H, B} \in \{+1, −1\}^n and . By define such that , \mathbf{C} \in \{+1,−1\}^n such that and such that . Also the optimal solution are solved:
- By average across the channel first and get which contain scaling factors for all sub-tensors in the input . We have:
- To decrease the information loss during the binarization, the structure of convolution block is changed to:

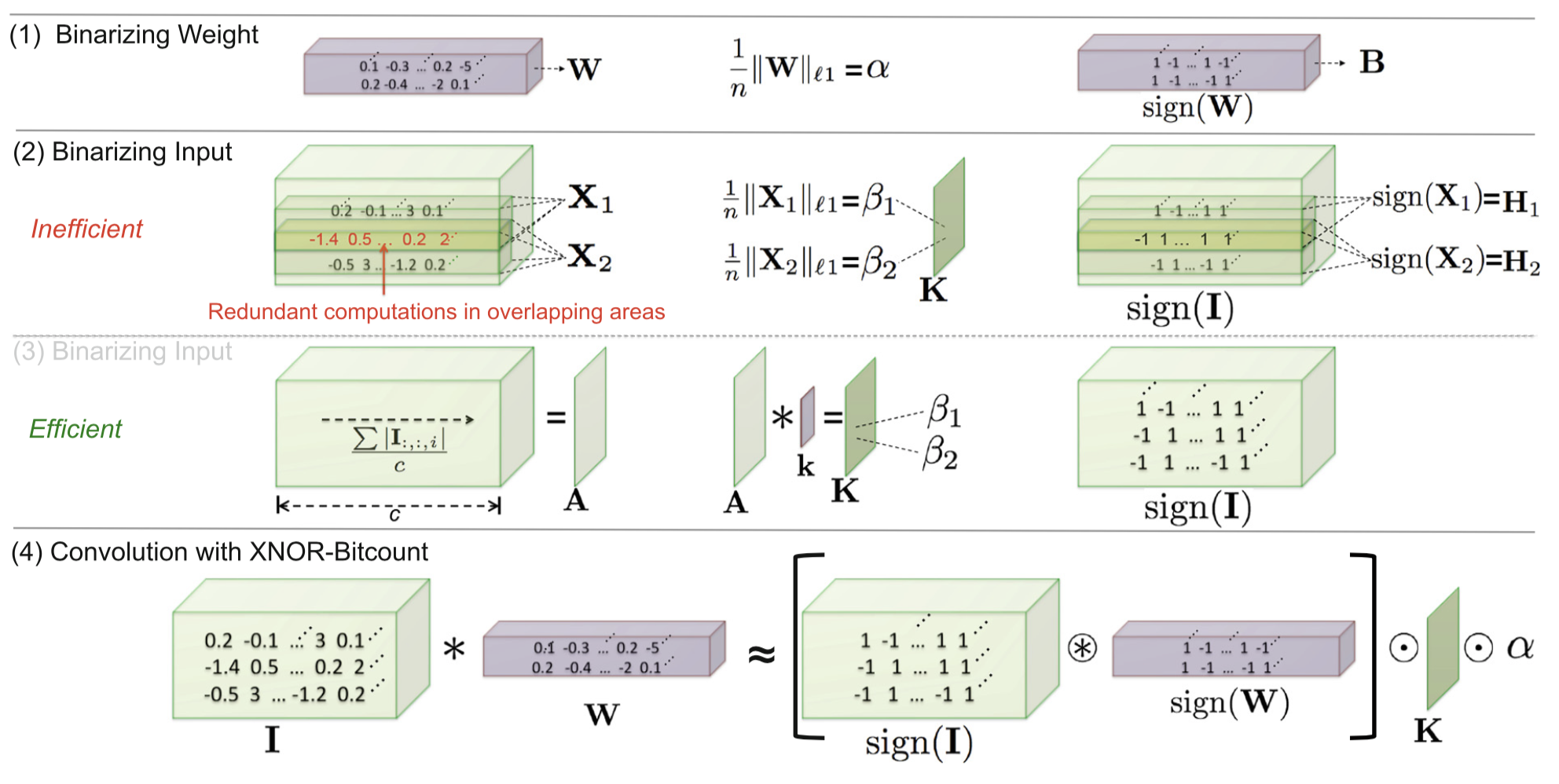
The key difference of our method is using a scaling-factor, which does not change the order of efficiency while providing a significant improvement in accuracy.
Binarized neural networks Github
This work is an extension of , and also published as .
- The gradient was calculated using the straight through estimator , which preserves the gradient’s information and cancels the gradient when r is too large.
- The weights are constrained to real-value between , and function is used to binarize the activations and weights.
- Shifted based version of BatchNorm and Adam were introduced for speeding up computation.
Our method of training BNNs can be seen as a variant of Dropout, in which instead of randomly setting half of the activations to zero when computing the parameter gradients, we binarize both the activations and the weights.
DoReFa-Net
The author extend the definition of Straight Through Estimator and proposed several STEs, one to quantize the activation with k-bit number, and the other is the k-bit extended version of the STE used in XNOR-net.
- The weights are limited in the range of by .
- Not only the activations and the weights, the gradients are also quantized with k-bit number.
We find that weights and activations can be deterministically quantized while gradients need to be stochastically quantized.
Reference
[1]. Hinton, G. Neural networks for machine learning. Coursera, video lectures, 2012.
[2]. Y. Bengio, N. Léonard, and A. Courville, “Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation,” arXiv.org, vol. cs.LG. p. arXiv:1308.3432, 15-Sep-2013.
[3]. M. Kim and P. Smaragdis, “Bitwise Neural Networks,” presented at the International Conference on Machine Learning, 2015, pp. 1–5.
[4]. M. Courbariaux, Y. Bengio, and J.-P. David, “BinaryConnect: Training Deep Neural Networks with binary weights during propagations,” presented at the Advances in Neural Information Processing Systems, 2015, pp. 1–9.
[5]. Z. Lin, M. Courbariaux, R. Memisevic, and Y. Bengio, “Neural Networks with Few Multiplications,” presented at the International Conference on Learning Representations, 2016, pp. 1–9.
[6]. M. Rastegari, V. Ordonez, J. Redmon, and A. Farhadi, “XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks,” presented at the European conference on computer vision, Amsterdam, The Netherlands, 2016, pp. 525–542.
[7]. I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y. Bengio, “Binarized neural networks,” presented at the Advances in Neural Information Processing Systems, 2016, pp. 4114–4122.
[8]. M. Courbariaux, I. Hubara, D. Soudry, R. El-Yaniv, and Y. Bengio, “Binarized Neural Networks: Training Neural Networks with Weights and Activations Constrained to +1 or −1,” arXiv.org, vol. cs.LG. p. arXiv:1602.0283, 17-Mar-2016.
[9]. I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y. Bengio, “Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations.,” arXiv.org, vol. cs.NE. p. arXiv:1609.07061, 22-Sep-2016.
[10]. S. Zhou, Y. Wu, Z. Ni, X. Zhou, H. Wen, and Y. Zou, “DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients,” arXiv.org, vol. cs.NE. p. arXiv:1606.06160, 02-Feb-2018.